
I am currently a technical staff member at  DeepSeek AI, leading the multimodal group.
This group, responsible for multimodal pre-training and post-training, focuses on advancing the multimodal capabilities of DeepSeek's large language models (LLMs).
I am driven by the mission to expand the frontiers of machine intelligence and weave it into the fabric of everyday life, ultimately augmenting human potential.
DeepSeek AI, leading the multimodal group.
This group, responsible for multimodal pre-training and post-training, focuses on advancing the multimodal capabilities of DeepSeek's large language models (LLMs).
I am driven by the mission to expand the frontiers of machine intelligence and weave it into the fabric of everyday life, ultimately augmenting human potential.
I obtained my Ph.D degree at Peking University (PKU) in 2024, supervised by Professor Gang Zeng. Before that, I received my Bachelor’s degree at Peking University in July 2019.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Peking UniversityPh.D. StudentSep. 2019 - Jul. 2024
Peking UniversityPh.D. StudentSep. 2019 - Jul. 2024 -
Peking UniversityB.S. in Computer ScienceSep. 2015 - Jul. 2019
Academic Service
-
Journal reviewer: IJCV, TPAMI, TIP, TCSVT, Neurocomputing, CVIU.
-
Conference reviewer: CVPR, ECCV, ICCV, NeurIPS, ICML, AAAI
Honors & Awards
-
WAIC Yunfan Award (云帆奖)2025
-
Standford World's Top 2% Scientists2025
-
Outstanding Graduate, Peking University2024
-
National Scholarship, (Ministry of Education, PRC)2021, 2022, 2023
-
Merit Student, PKU2020, 2021, 2022, 2023
-
Top 10 Outstanding Researcher (学术十杰), PKU2021
-
Huawei Scholarship2021
-
Award for Academic Innovation, PKU2021
-
Schlumberger Scholarship2020
-
Award for Excellent Research, PKU2017, 2018, 2019
Experience
-
 DeepSeekAGI ResearcherApr. 2024 - now
DeepSeekAGI ResearcherApr. 2024 - now -
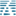 Shanghai Artificial Intelligence LaboratoryResearch Intern, directed by Dr. Wenhai Wang and Dr. Jifeng Dai.Dec. 2022 - Nov. 2023
Shanghai Artificial Intelligence LaboratoryResearch Intern, directed by Dr. Wenhai Wang and Dr. Jifeng Dai.Dec. 2022 - Nov. 2023 -

-
 Microsoft Research Aisa (MSRA)Research Intern, directed by Dr. Jingdong Wang.Jun. 2020 - Dec. 2021
Microsoft Research Aisa (MSRA)Research Intern, directed by Dr. Jingdong Wang.Jun. 2020 - Dec. 2021 -
 Sensetime ResearchResearch Intern, directed by Dr. Kwan-Yee Lin and Dr. Wayne (Wenyan) Wu.Apr. 2019 - May. 2020
Sensetime ResearchResearch Intern, directed by Dr. Kwan-Yee Lin and Dr. Wayne (Wenyan) Wu.Apr. 2019 - May. 2020
News
Selected Projects and Papers (view all )
Janus-Series: Unified Multimodal Understanding and Generation Models
DeepSeek
Project lead and core contributor.
Abstract
[Paper: Janus-Pro] [Paper: Janus (CVPR 2025)] [Paper: JanusFlow (CVPR 2025)]
Janus-Series: Unified Multimodal Understanding and Generation Models
DeepSeek
Project lead and core contributor.
Abstract
[Paper: Janus-Pro] [Paper: Janus (CVPR 2025)] [Paper: JanusFlow (CVPR 2025)]
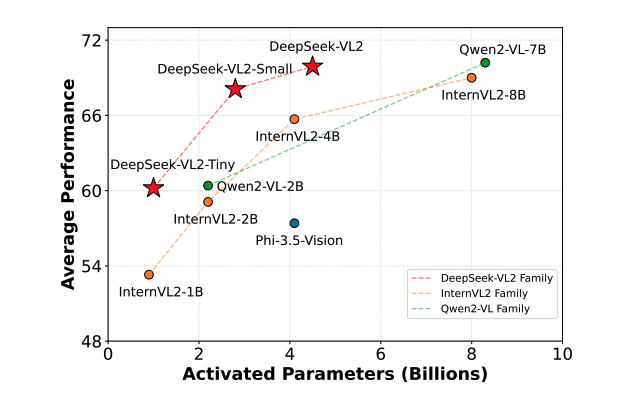
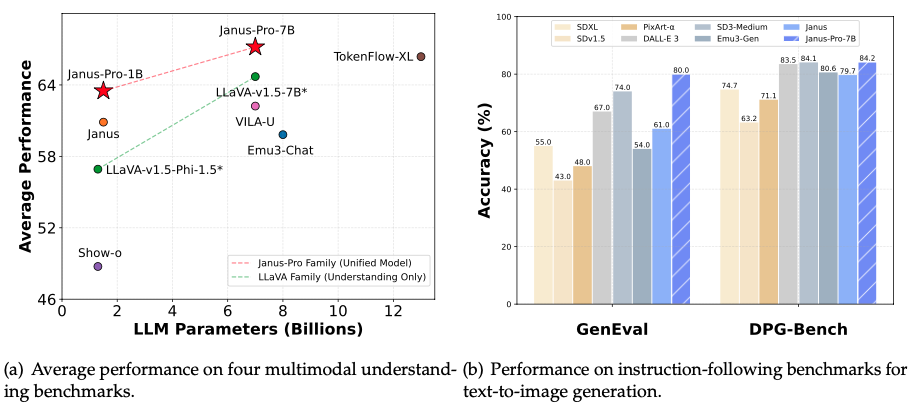
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek
Project co-lead and core contributor.
Abstract
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek
Project co-lead and core contributor.
Abstract
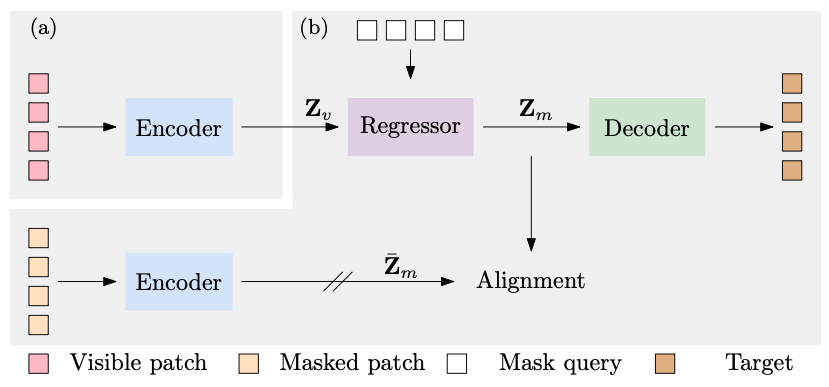
CAE: Context Autoencoder for Self-Supervised Representation Learning
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, Jingdong Wang
International Journal of Computer Vision (IJCV) 2023
Abstract
CAE: Context Autoencoder for Self-Supervised Representation Learning
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, Jingdong Wang
International Journal of Computer Vision (IJCV) 2023
Abstract
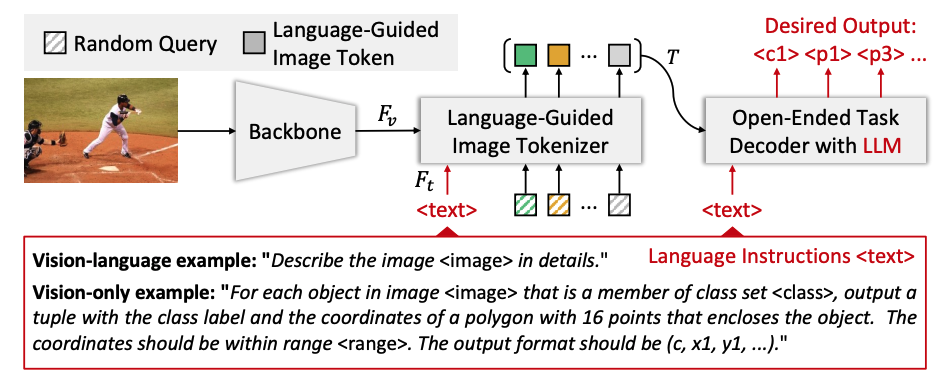
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
Wenhai Wang*, Zhe Chen*, Xiaokang Chen*, Jiannan Wu*, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai (* equal contribution)
Neural Information Processing Systems (NeurIPS) 2023
Abstract
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
Wenhai Wang*, Zhe Chen*, Xiaokang Chen*, Jiannan Wu*, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai (* equal contribution)
Neural Information Processing Systems (NeurIPS) 2023
Abstract
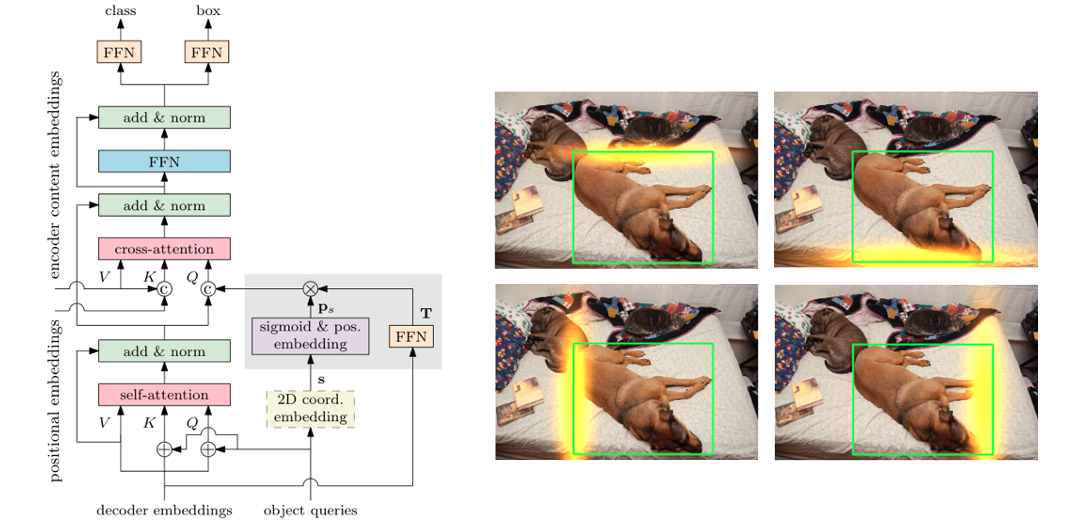
Conditional DETR for Fast Training Convergence
Xiaokang Chen*, Depu Meng*, Zejia Fan, Gang Zeng, Houqiang Li,, Yuhui Yuan,, Lei Sun, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2021
Abstract
Conditional DETR for Fast Training Convergence
Xiaokang Chen*, Depu Meng*, Zejia Fan, Gang Zeng, Houqiang Li,, Yuhui Yuan,, Lei Sun, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2021
Abstract
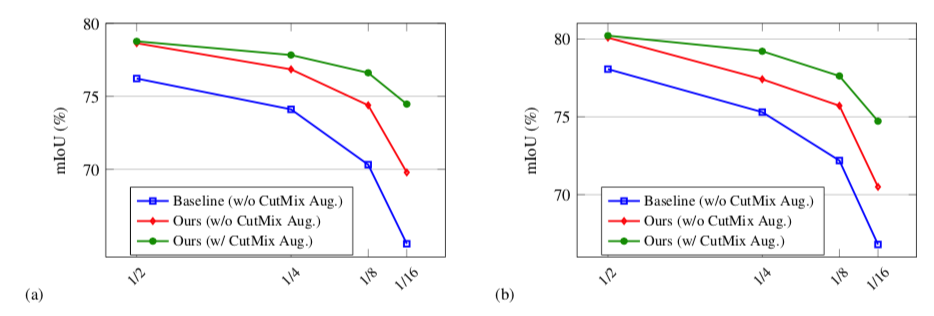
CPS: Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Abstract
[Paper] [Code] [Poster] [Slides] [Video Talk] [中文解读]
CPS: Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Abstract