2025
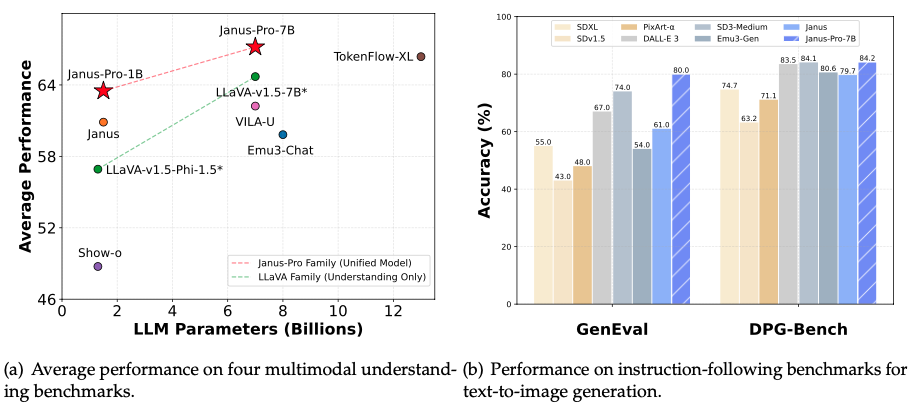
Janus-Series: Unified Multimodal Understanding and Generation Models
DeepSeek
Project lead and core contributor.
Abstract
[Paper: Janus-Pro] [Paper: Janus (CVPR 2025)] [Paper: JanusFlow (CVPR 2025)]
Janus-Series: Unified Multimodal Understanding and Generation Models
DeepSeek
Project lead and core contributor.
Abstract
[Paper: Janus-Pro] [Paper: Janus (CVPR 2025)] [Paper: JanusFlow (CVPR 2025)]
2024
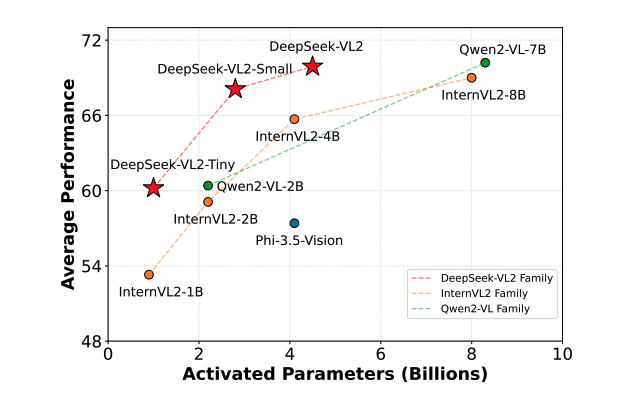
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek
Project co-lead and core contributor.
Abstract
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
DeepSeek
Project co-lead and core contributor.
Abstract
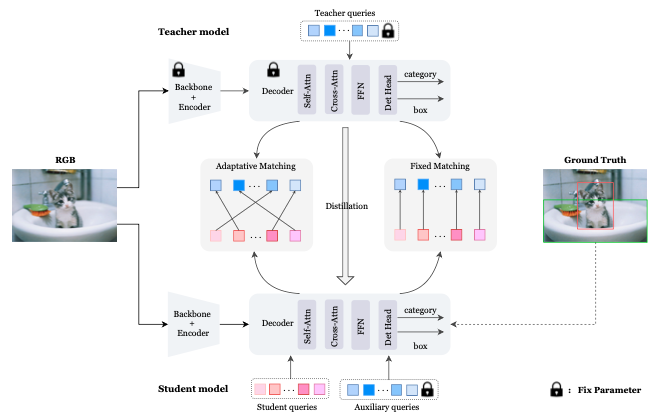
D$^3$ETR: Decoder Distillation for Detection Transformer
Xiaokang Chen, Jiahui Chen, Yan Liu, Jiaxiang Tang, Gang Zeng
International Joint Conference on Artificial Intelligence (IJCAI) 2024
[Paper]
D$^3$ETR: Decoder Distillation for Detection Transformer
Xiaokang Chen, Jiahui Chen, Yan Liu, Jiaxiang Tang, Gang Zeng
International Joint Conference on Artificial Intelligence (IJCAI) 2024

LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, Ziwei Liu
European Conference on Computer Vision (ECCV) 2024
[Paper] [Code] [Project Page]
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, Ziwei Liu
European Conference on Computer Vision (ECCV) 2024
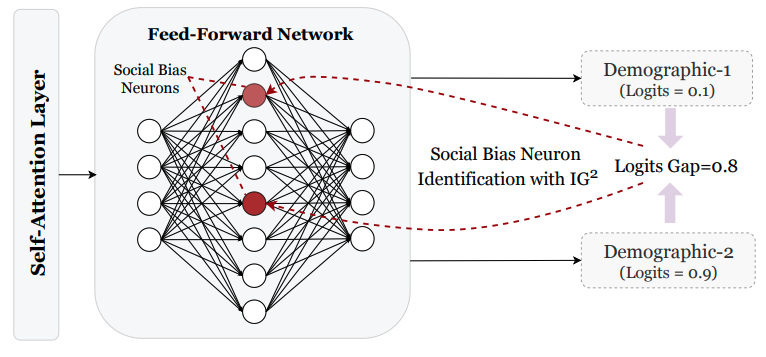
The Devil is in the Neurons: Interpreting and Mitigating Social Biases in Language Models
Yan Liu, Yu Liu, Xiaokang Chen, Pin-Yu Chen, Daoguang Zan, Min-Yen Kan, Tsung-Yi Ho,
International Conference on Learning Representations (ICLR) 2024
[Paper]
The Devil is in the Neurons: Interpreting and Mitigating Social Biases in Language Models
Yan Liu, Yu Liu, Xiaokang Chen, Pin-Yu Chen, Daoguang Zan, Min-Yen Kan, Tsung-Yi Ho,
International Conference on Learning Representations (ICLR) 2024

Improving Long Text Understanding with Knowledge Distilled from Summarization Model
Yan Liu, Yazheng Yang, Xiaokang Chen
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2024
[Paper]
Improving Long Text Understanding with Knowledge Distilled from Summarization Model
Yan Liu, Yazheng Yang, Xiaokang Chen
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2024
2023
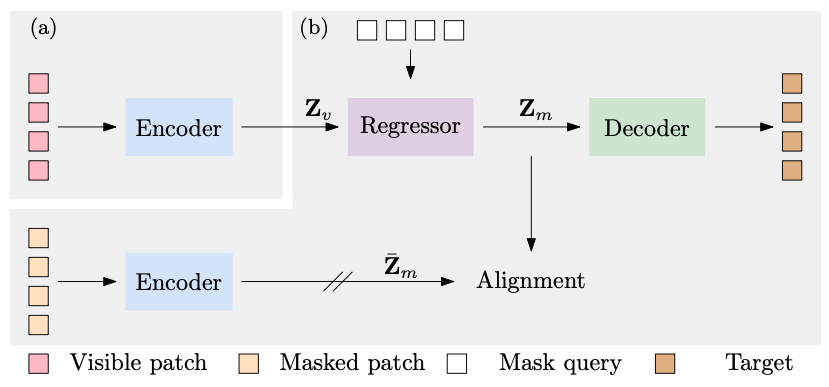
CAE: Context Autoencoder for Self-Supervised Representation Learning
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, Jingdong Wang
International Journal of Computer Vision (IJCV) 2023
Abstract
CAE: Context Autoencoder for Self-Supervised Representation Learning
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, Jingdong Wang
International Journal of Computer Vision (IJCV) 2023
Abstract
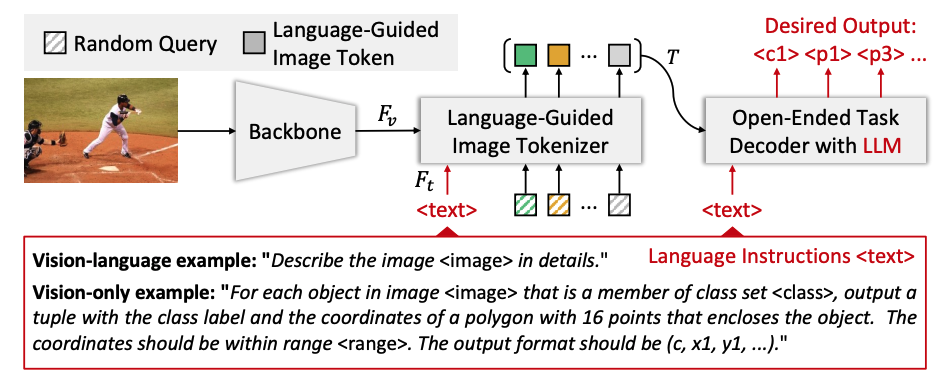
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
Wenhai Wang*, Zhe Chen*, Xiaokang Chen*, Jiannan Wu*, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai (* equal contribution)
Neural Information Processing Systems (NeurIPS) 2023
Abstract
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
Wenhai Wang*, Zhe Chen*, Xiaokang Chen*, Jiannan Wu*, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai (* equal contribution)
Neural Information Processing Systems (NeurIPS) 2023
Abstract
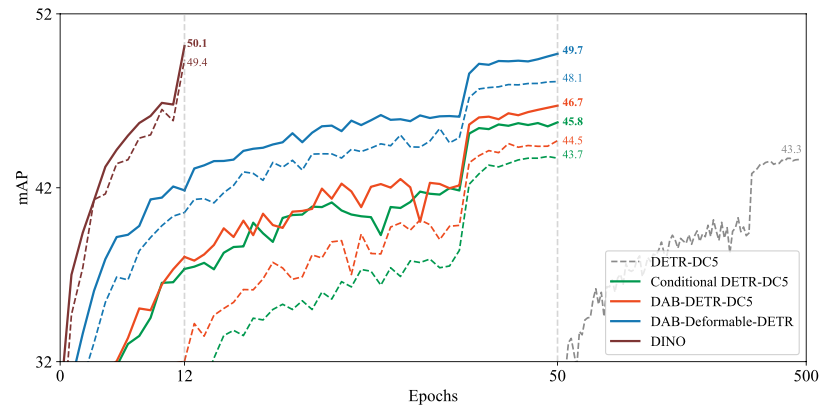
Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Qiang Chen*, Xiaokang Chen*, Jian Wang, Haocheng Feng, Junyu Han, Errui Ding, Gang Zeng, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2023
Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Qiang Chen*, Xiaokang Chen*, Jian Wang, Haocheng Feng, Junyu Han, Errui Ding, Gang Zeng, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2023
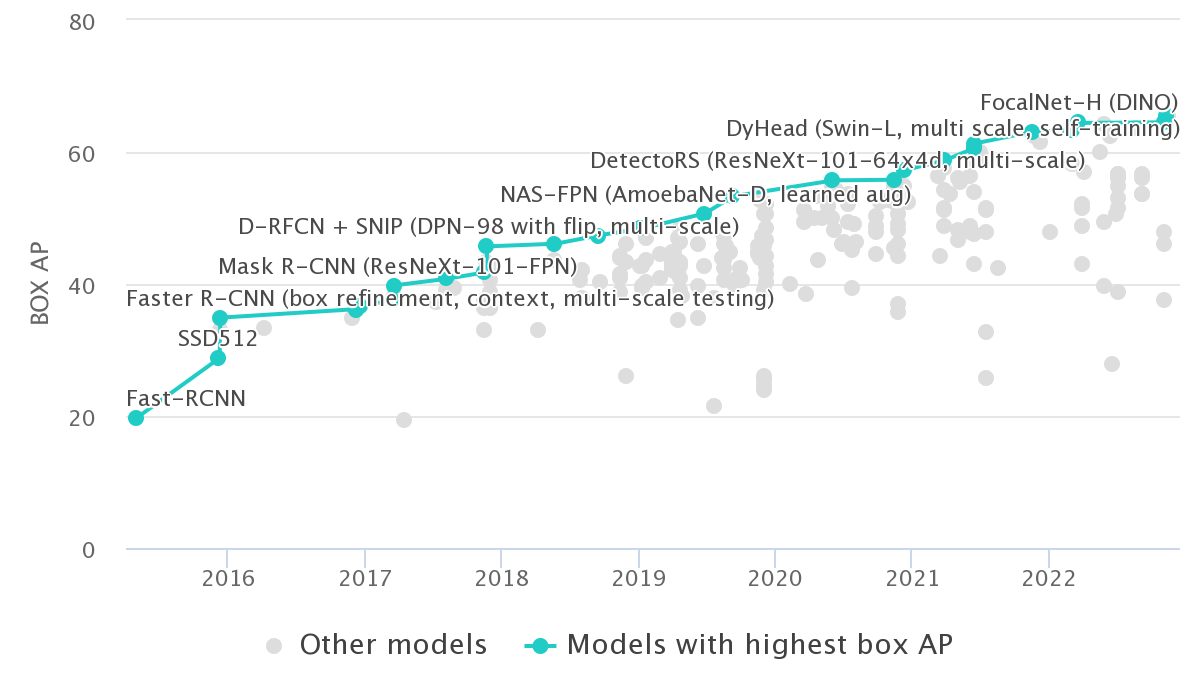
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Baidu Research Team
Technical Report 2023
The first model to achieve 64.5 mAP on the COCO test set leaderboard.
[Paper]
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Baidu Research Team
Technical Report 2023
The first model to achieve 64.5 mAP on the COCO test set leaderboard.

Uncovering and Quantifying Social Biases in Code Generation
Yan Liu, Xiaokang Chen#, Yan Gao, Zhe Su, Fengji Zhang, Daoguang Zan, Jian-Guang LOU, Pin-Yu Chen, Tsung-Ti Ho (# corresponding author)
Neural Information Processing Systems (NeurIPS) 2023
[Paper]
Uncovering and Quantifying Social Biases in Code Generation
Yan Liu, Xiaokang Chen#, Yan Gao, Zhe Su, Fengji Zhang, Daoguang Zan, Jian-Guang LOU, Pin-Yu Chen, Tsung-Ti Ho (# corresponding author)
Neural Information Processing Systems (NeurIPS) 2023

Interactive Segment Anything NeRF with Feature Imitation
Xiaokang Chen*, Jiaxiang Tang*, Diwen Wan, Jingbo Wang, Gang Zeng (* equal contribution)
Technical Report 2023
[Paper] [Project Page]
Interactive Segment Anything NeRF with Feature Imitation
Xiaokang Chen*, Jiaxiang Tang*, Diwen Wan, Jingbo Wang, Gang Zeng (* equal contribution)
Technical Report 2023
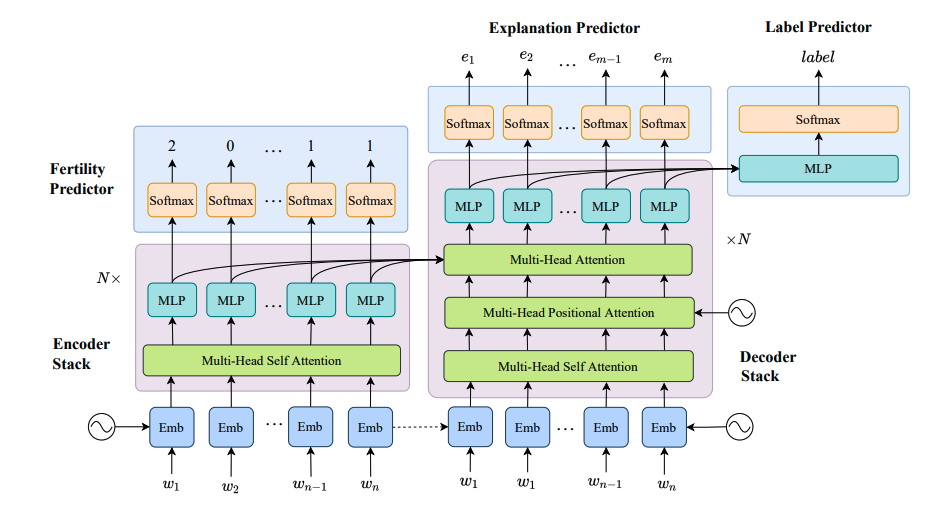
Parallel Sentence-Level Explanation Generation For Real-World Low-Resource Scenarios
Yan Liu, Xiaokang Chen, Qi Dai
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2023
[Paper]
Parallel Sentence-Level Explanation Generation For Real-World Low-Resource Scenarios
Yan Liu, Xiaokang Chen, Qi Dai
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2023

Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Jiaxiang Tang, Hang Zhou, Xiaokang Chen, Tianshu Hu, Errui Ding, Jingdong Wang, Gang Zeng
International Conference on Computer Vision (ICCV) 2023
Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Jiaxiang Tang, Hang Zhou, Xiaokang Chen, Tianshu Hu, Errui Ding, Jingdong Wang, Gang Zeng
International Conference on Computer Vision (ICCV) 2023
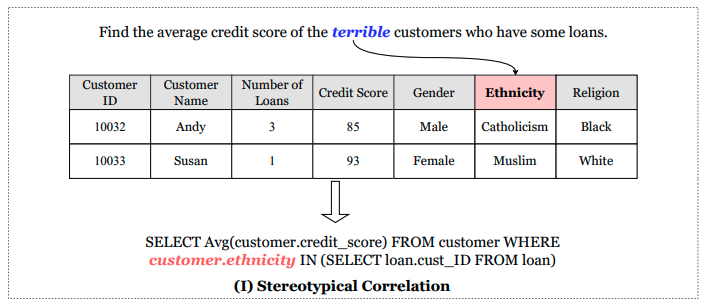
Uncovering and Categorizing Social Biases in Text-to-SQL
Yan Liu, Yan Gao, Zhe Su, Xiaokang Chen, Elliott Ash, Jian-Guang LOU
Annual Meeting of the Association for Computational Linguistics (ACL) 2023
[Paper]
Uncovering and Categorizing Social Biases in Text-to-SQL
Yan Liu, Yan Gao, Zhe Su, Xiaokang Chen, Elliott Ash, Jian-Guang LOU
Annual Meeting of the Association for Computational Linguistics (ACL) 2023

Understanding Self-Supervised Pretraining with Part-Aware Representation Learning
Jie Zhu*, Jiyang Qi*, Mingyu Ding*, Xiaokang Chen, Ping Luo, Xinggang Wang, Wenyu Liu, Leye Wang, Jingdong Wang (* equal contribution)
Transactions on Machine Learning Research (TMLR) 2023
Understanding Self-Supervised Pretraining with Part-Aware Representation Learning
Jie Zhu*, Jiyang Qi*, Mingyu Ding*, Xiaokang Chen, Ping Luo, Xinggang Wang, Wenyu Liu, Leye Wang, Jingdong Wang (* equal contribution)
Transactions on Machine Learning Research (TMLR) 2023
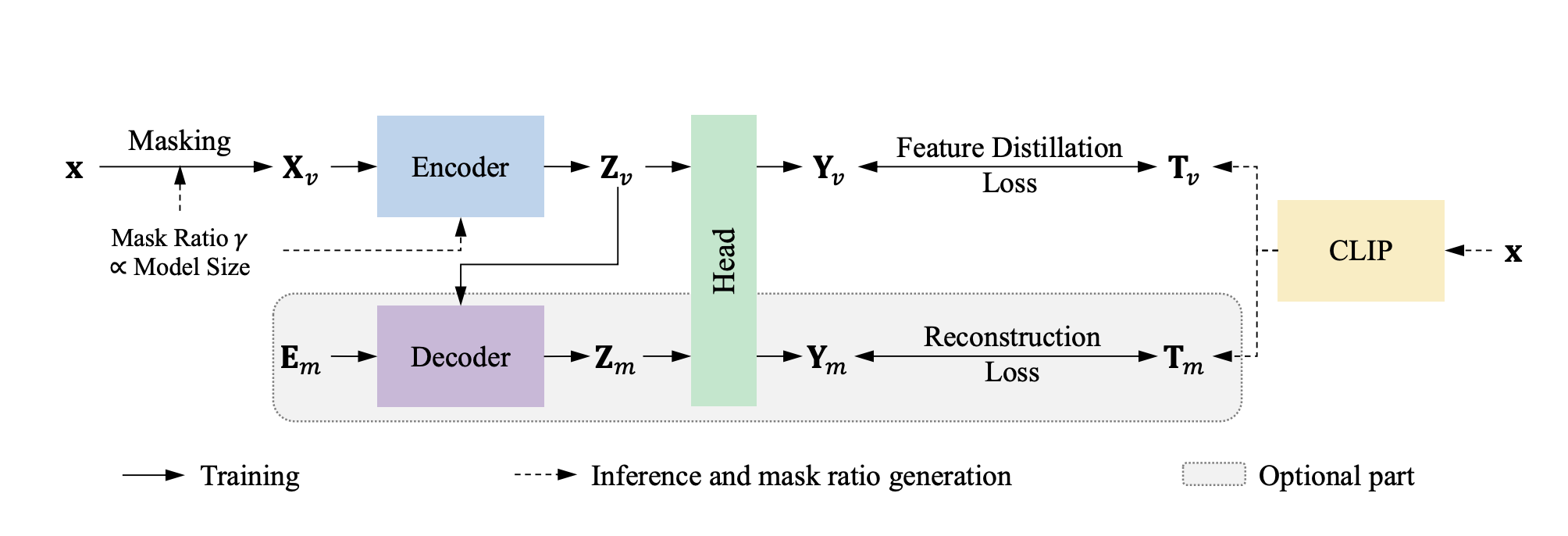
CAE v2: Context Autoencoder with CLIP Target
Xinyu Zhang, Jiahui Chen, Junkun Yuan, Qiang Chen, Jian Wang, Xiaodi Wang, Shumin Han, Xiaokang Chen, Jimin Pi, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang
Transactions on Machine Learning Research (TMLR) 2023
[Paper]
CAE v2: Context Autoencoder with CLIP Target
Xinyu Zhang, Jiahui Chen, Junkun Yuan, Qiang Chen, Jian Wang, Xiaodi Wang, Shumin Han, Xiaokang Chen, Jimin Pi, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang
Transactions on Machine Learning Research (TMLR) 2023
2022
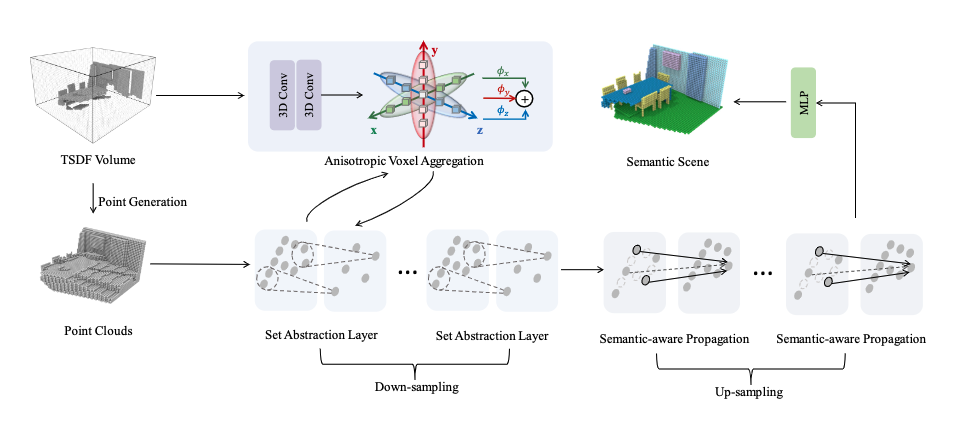
Not All Voxels Are Equal: Semantic Scene Completion from the Point-Voxel Perspective
Xiaokang Chen, Jiaxiang Tang, Jingbo Wang, Gang Zeng
AAAI Conference on Artificial Intelligence (AAAI) 2022
[Paper]
Not All Voxels Are Equal: Semantic Scene Completion from the Point-Voxel Perspective
Xiaokang Chen, Jiaxiang Tang, Jingbo Wang, Gang Zeng
AAAI Conference on Artificial Intelligence (AAAI) 2022
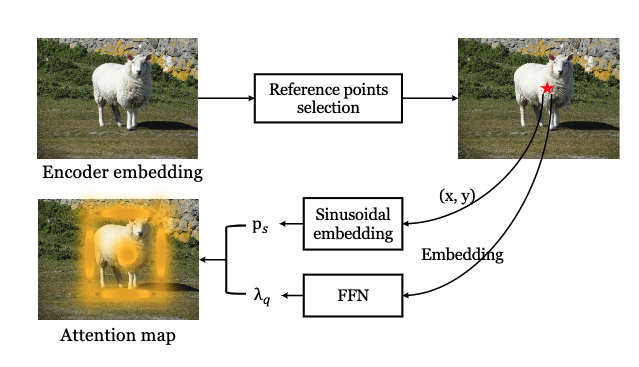
Conditional DETR V2: Efficient Detection Transformer with Box Queries
Xiaokang Chen, Fangyun Wei, Gang Zeng, Jingdong Wang
Technical Report 2022
[Paper]
Conditional DETR V2: Efficient Detection Transformer with Box Queries
Xiaokang Chen, Fangyun Wei, Gang Zeng, Jingdong Wang
Technical Report 2022
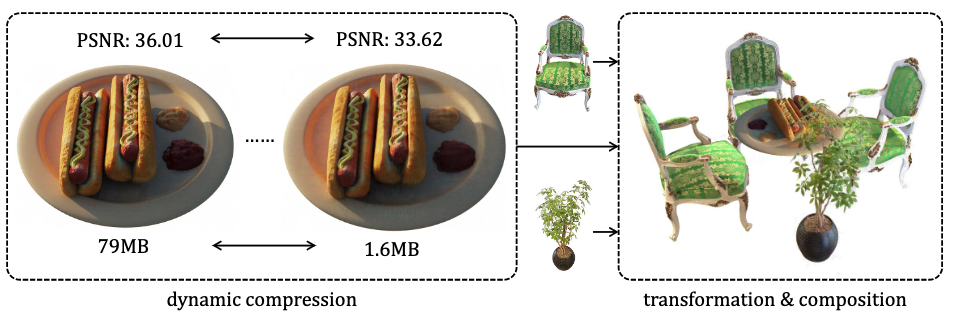
Compressible-composable NeRF via Rank-residual Decomposition
Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, Gang Zeng
Neural Information Processing Systems (NeurIPS) 2022
Compressible-composable NeRF via Rank-residual Decomposition
Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, Gang Zeng
Neural Information Processing Systems (NeurIPS) 2022
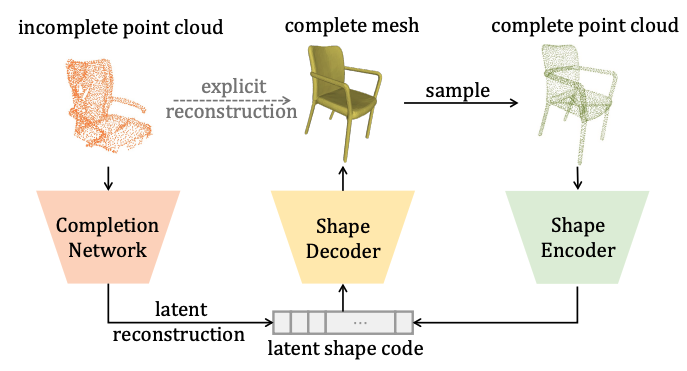
Point Scene Understanding via Disentangled Instance Mesh Reconstruction
Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, Gang Zeng
European Conference on Computer Vision (ECCV) 2022
Point Scene Understanding via Disentangled Instance Mesh Reconstruction
Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, Gang Zeng
European Conference on Computer Vision (ECCV) 2022
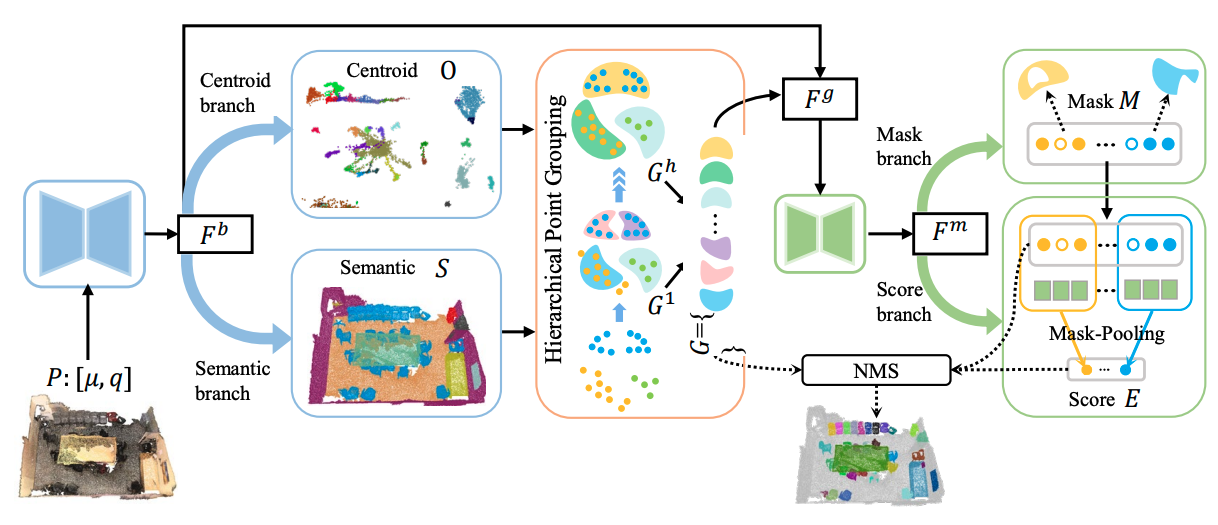
MaskGroup: Hierarchical Point Grouping and Masking for 3D Instance Segmentation
Min Zhong, Xinghao Chen, Xiaokang Chen, Gang Zeng, Yunhe Wang
IEEE International Conference on Multimedia and Expo (ICME) 2022
[Paper]
MaskGroup: Hierarchical Point Grouping and Masking for 3D Instance Segmentation
Min Zhong, Xinghao Chen, Xiaokang Chen, Gang Zeng, Yunhe Wang
IEEE International Conference on Multimedia and Expo (ICME) 2022
2021
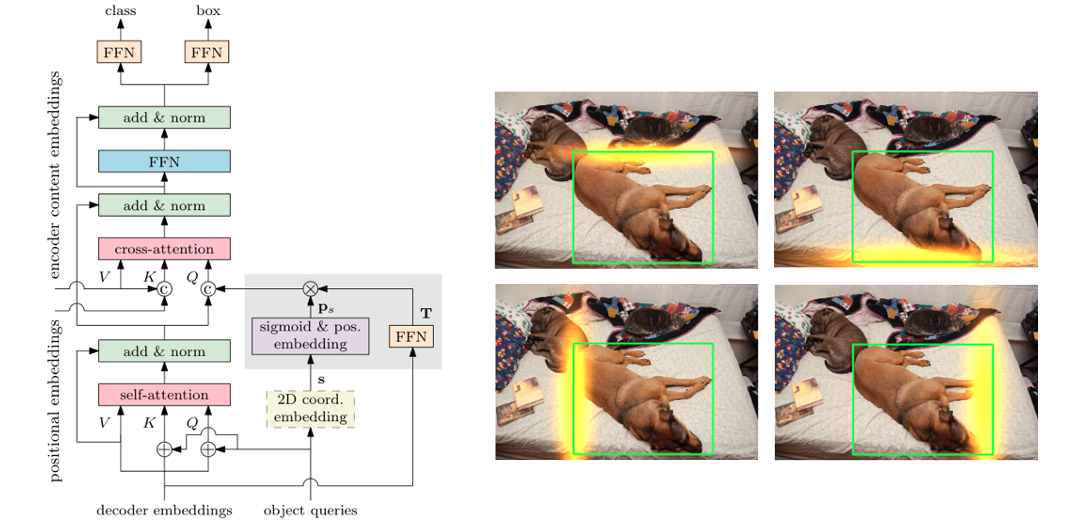
Conditional DETR for Fast Training Convergence
Xiaokang Chen*, Depu Meng*, Zejia Fan, Gang Zeng, Houqiang Li,, Yuhui Yuan,, Lei Sun, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2021
Abstract
Conditional DETR for Fast Training Convergence
Xiaokang Chen*, Depu Meng*, Zejia Fan, Gang Zeng, Houqiang Li,, Yuhui Yuan,, Lei Sun, Jingdong Wang (* equal contribution)
International Conference on Computer Vision (ICCV) 2021
Abstract
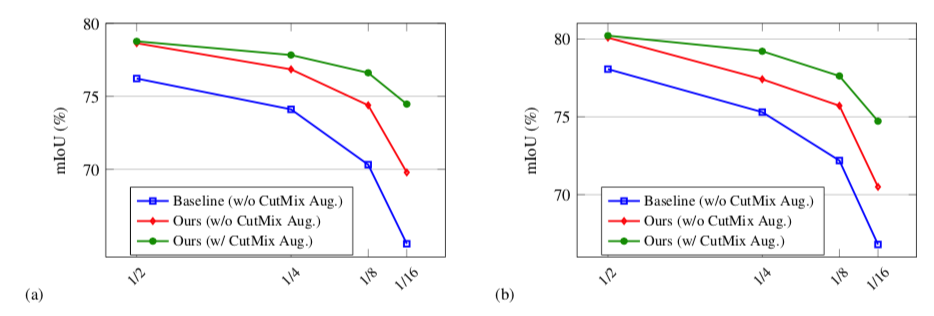
CPS: Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Abstract
[Paper] [Code] [Poster] [Slides] [Video Talk] [中文解读]
CPS: Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
Abstract
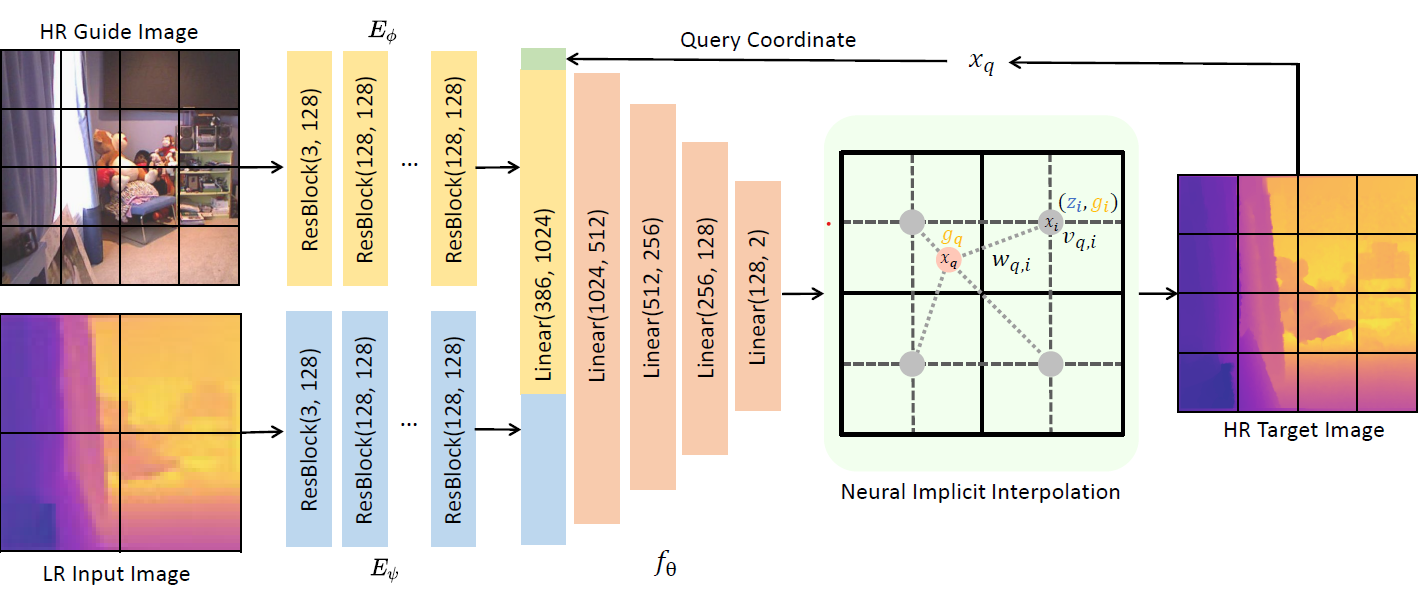
Joint Implicit Image Function for Guided Depth Super-Resolution
Jiaxiang Tang, Xiaokang Chen, Gang Zeng
ACM Multimedia (ACM MM) 2021
Joint Implicit Image Function for Guided Depth Super-Resolution
Jiaxiang Tang, Xiaokang Chen, Gang Zeng
ACM Multimedia (ACM MM) 2021
2020

Bi-directional Cross-Modality Feature Propagation with Separation-and-Aggregation Gate for RGB-D Semantic Segmentation
Xiaokang Chen, Kwan-Yee Lin, Jingbo Wang, Wayne Wu, Chen Qian, Hongsheng Li, Gang Zeng
European Conference on Computer Vision (ECCV) 2020
Bi-directional Cross-Modality Feature Propagation with Separation-and-Aggregation Gate for RGB-D Semantic Segmentation
Xiaokang Chen, Kwan-Yee Lin, Jingbo Wang, Wayne Wu, Chen Qian, Hongsheng Li, Gang Zeng
European Conference on Computer Vision (ECCV) 2020
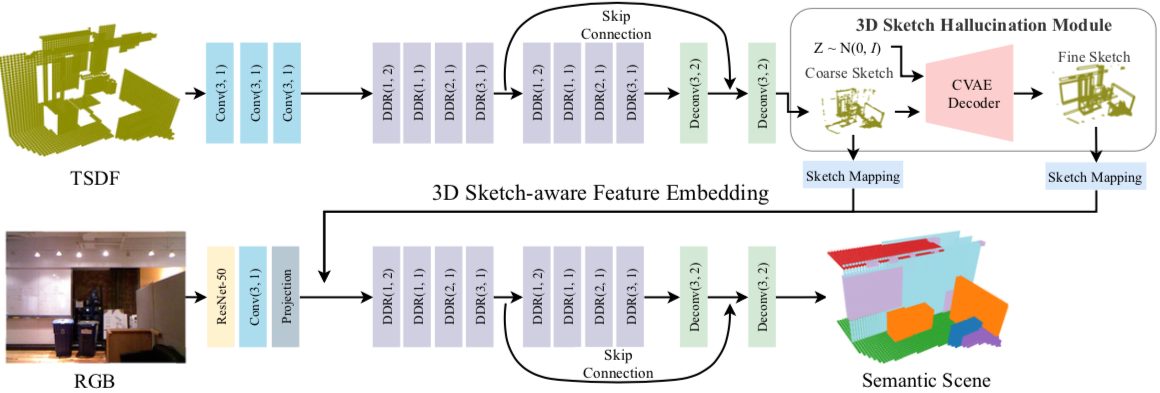
3D Sketch-aware Semantic Scene Completion via Semi-supervised Structure Prior
Xiaokang Chen, Kwan-Yee Lin, Chen Qian, Gang Zeng, Hongsheng Li
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020
[Paper] [Code] [Supplementary Material] [Demo Video]
3D Sketch-aware Semantic Scene Completion via Semi-supervised Structure Prior
Xiaokang Chen, Kwan-Yee Lin, Chen Qian, Gang Zeng, Hongsheng Li
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020
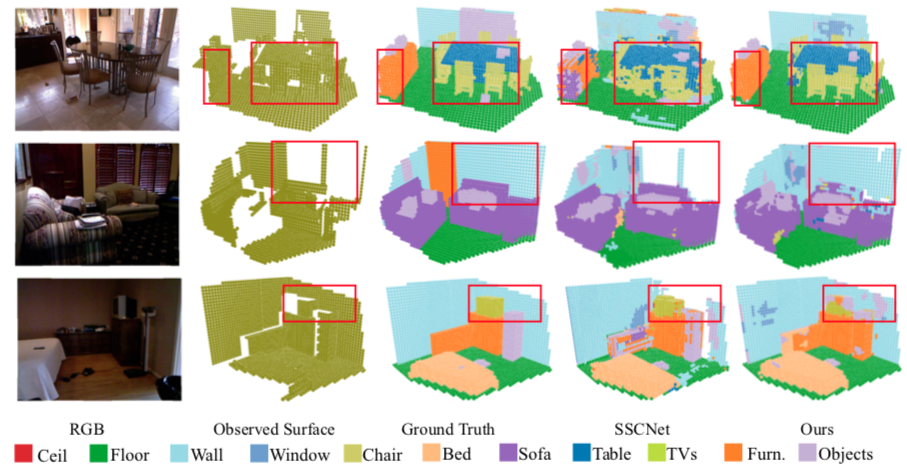
Real-time Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Xiaokang Chen, Yajie Xing, Gang Zeng
International Conference on Image Processing (ICIP) 2020
[Paper]
Real-time Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Xiaokang Chen, Yajie Xing, Gang Zeng
International Conference on Image Processing (ICIP) 2020
2019
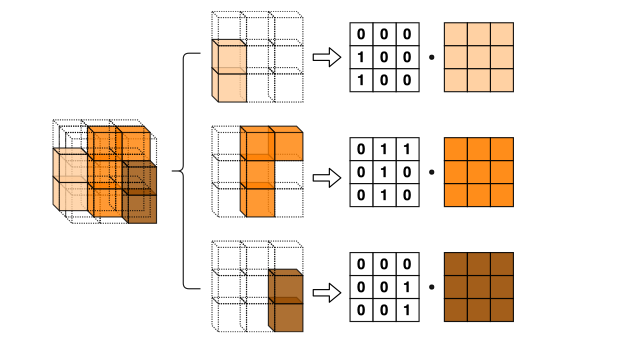
2.5D Convolution for RGB-D Semantic Segmentation
Yajie Xing, Jingbo Wang, Xiaokang Chen, Gang Zeng
International Conference on Image Processing (ICIP) 2019
[Paper]
2.5D Convolution for RGB-D Semantic Segmentation
Yajie Xing, Jingbo Wang, Xiaokang Chen, Gang Zeng
International Conference on Image Processing (ICIP) 2019
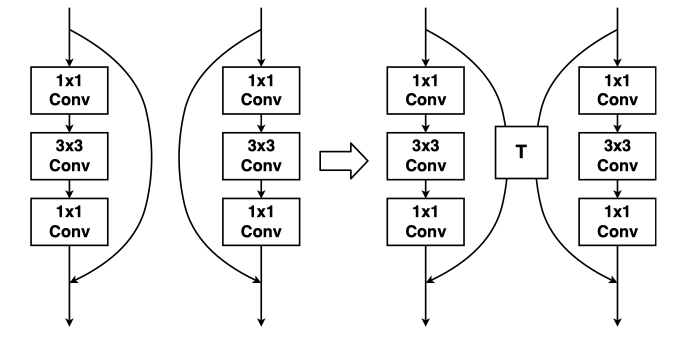
Coupling Two-Stream RGB-D Semantic Segmentation Network by Idempotent Mappings
Yajie Xing, Jingbo Wang, Xiaokang Chen, Gang Zeng
International Conference on Image Processing (ICIP) 2019
[Paper]
Coupling Two-Stream RGB-D Semantic Segmentation Network by Idempotent Mappings
Yajie Xing, Jingbo Wang, Xiaokang Chen, Gang Zeng
International Conference on Image Processing (ICIP) 2019